人实现意图的最终目标,是将人的【想法】直接通过【外部代理】完全实现。当前社会有【代理人】的概念,即通过某个人来实现我们的想法。如果机器足够智能时,则【代理人】可以被【代理机器】替代,也就是机器也可以实现我们的想法。
从工具的角度来说,机器也是一种工具,而传统的工具是指辅助人类实现某种生产过程,如果工具足够智能,也可以升级为代理的角色,完全或部分替代人类的生产。当前我们所发明的大部分工具,是一种从生产方式转变为另一种生产方式,根本目的在于提高生产效率。
当工具完全替换人的劳动时,生产效率的提高,通过对工具的升级来实现,而升级工具则通过人来实现,因此人的生产工作转换为间接提供生产工具,而非直接参与生产。
按照如上的推导,工具实现的代理本质也是一种工具。人们在直接或间接参与生产时,都需要工具来实现,如果代理足够智能,那么人们的工作会集中在生产和维护代理上,而代理则直接参与生产。类似于在交通工具发明前,人使用自己的双腿走路,交通工具发明后,则人大部分情况会使用交通工具作为代理实现出行的目的。
类似的概念,人们在操作一项任务时,如果代理足够智能,那么人们就可以直接下达指令,实现自己的操作意图。本文主要研究在电视内容消费领域,用户的意图实现路径和大模型带来的变化。
1.用户的意图实现路径
用户意图实现可以分为6步。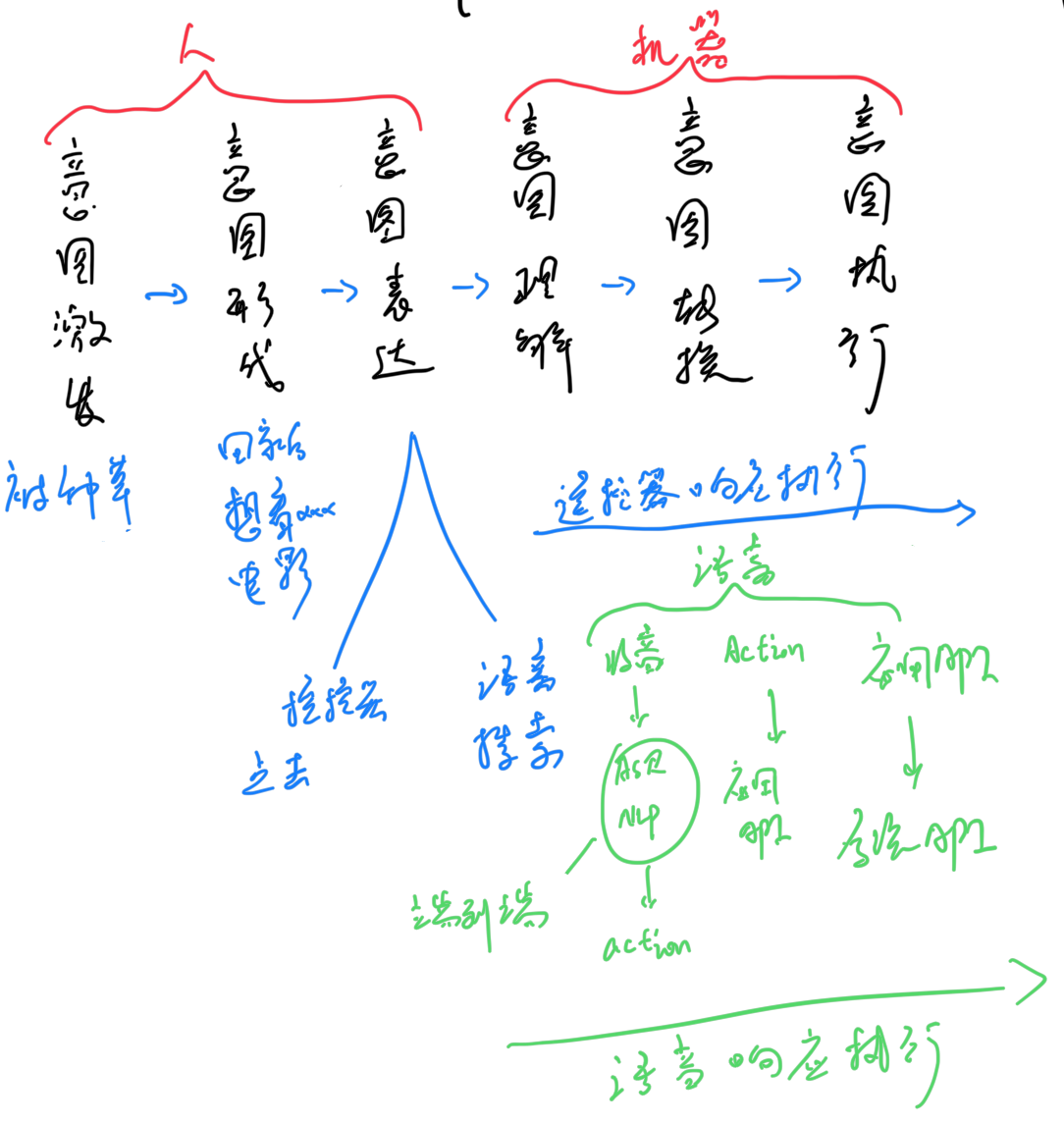
1.1 意图背景潜入
用户作为主导,通过日常生活的广告和亲友推荐被“种草”,比如某某儿童教育软件或电视的某个儿童教育场景不错
1.2 意图形成
在某个特殊场景下,用户的潜在的意图背景会形成具体意图,比如回家了后,听说家人的某件事情后(发现小朋友英语不太好),该意图被激发,会形成“下载某个儿童教育软件”或“进入某个儿童教育场景”的意图。
1.3 意图表达
意图表达一般是用户主动完成,如果是使用电视的场景。有两种表达方式:
(1)通过遥控器功能,控制焦点移动到相关按钮上
(2)通过语音功能:会说“打开xxx软件”,“打开xxx”等表达该意图。
1.4 意图理解
意图理解在遥控器场景一般是用户或用户+机器完成,如果在语音等用户调用路径较短的场景,一般是机器主导完成。
(1)遥控器场景较为简单,用户意图理解通过用户自行的遥控器点击逻辑实现;如果涉及遥控器搜索,则是 用户理解的按键逻辑+机器搜索+用户筛选搜索结果+遥控器点击 实现;
(2)语音场景,机器通过对用户输入的音频做处理,输出音频理解后的待选择结果,用户再做二次确认后完成理解
1.5 意图转换
意图转换这里指机器把用户意图的高级调用转换到系统层面的低级调用阶段。
(1)遥控器场景比较简单,用户通过遥控器按钮,将意图转换为应用的api做场景的功能调度
(2)语音场景,在意图理解部分,用户的意图被理解成功后,转换为一系列action,各个action需要先下发到各个应用后,再由各个应用转换为api做场景的功能调度
1.6 意图执行
意图执行一般是指机器调用的执行阶段。
执行部分只最后的场景实现部分,遥控器场景和语音场景相同,应用api被触发后直接做功能调度,系统api和io等最终实现意图的执行
2.大模型带来的用户意图实现路径变化
2.1 意图理解部分
2.1.1 用户通过关键词唤醒语音助手
单个关键词的监听是当前主流方案,端侧性能可控。
目前体验待改善点: 对于用户侧,期望的是随时一句话可以唤醒并响应待识别内容。比如“小度我想看电影”而不是“小度小度”,“我想看电影”。端侧大模型如果理解能力不足则该部分无法改善,而全部放到云端,则速度体验和运营成本会比较高。
可关注的方向: 端侧语义理解大模型的性能需求降低和理解能力增强。
2.1.2 用户唤醒语音助手后,继续输出语音表达意图
目前体验待改善点(1): 唤醒后需要等待一段时间()再说识别的语音,否则语音助手无法识别意图。如果当前的语音助手已经在交谈中了,是不是不需要继续等唤醒,而是每句话都会进入识别意图? 可关注的方向: 当前的本地大模型是否可以持续处理用户意图,如果是和语音助手在交流,则可以响应,否则可以不响应或低参与度的响应。
目前体验待改善点(2): 当前只能识别到可以转换为文字的语音信息,无法识别到非文本类的语音信息。 可关注的方向:1. 训练端到端模型,tts的回复包含对应的感情。 2. 用户的情感和非文本信息与用户意图结合训练 意图的端到端模型,输出的待执行意图包含相关非文本的结果。也就是在不同的用户情感或健康状态下,模型回复不同的结果,比如闲聊包含用户健康改善建议或推荐更适合用户情感的节目等。
2.1.3 设备在输出意图识别和执行的过程中,用户通过关键词打断本次意图的后续任务
目前体验待改善点(1): 已经在交谈中了,是不是不需要通过唤醒来打断后,再进行识别意图? 可关注的方向: 端侧大模型实时拾音
并理解用户意图,根据用户意图确认是否继续和用户进行聊天或者打断当前的聊天而响应用户最新的用户聊天内容。
目前体验待改善点(2): 是否可以通过“等一下”、“不对”、“等等”等进行意图中的打断,而不仅仅是唤醒词来打断?
2.1.4 设备语义理解模块对用户音频进行意图理解
当前的设备使用云端或本地大模型进行用户音频理解,理解后转换为相应的action,分发到各个应用。
目前体验待改善点: 当前的大模型理解音频,一般是先将语音转为文字,再对文字做意图理解,针对理解的文字做回复。而实际的用户侧需求包括但不限于:理解音频输出音频,理解音频后执行指令并输出音频。
对于第一种理解音频输出音频,一般限于知识问答类。当前的普遍操作:音频转文字,文字理解,搜索知识库后输出文字,文字转音频,最后做回复给用户的音频播报操作。 可关注的方向 音频输入并结合多模态输入、到音频输出的知识问答大模型
对于第二种理解音频后执行指令并输出音频,一般限于用户意图执行类:在文字理解后,是搜索知识库后输出文字和执行的指令意图,文字部分转音频,做音频播报回复给用户,而指令部分经由设备进行执行操作。 可关注的方向 音频输入并结合多模态输入、到音频输出的领域大模型+知识问答大模型。
2.2 意图转换部分
各应用接收到语音发出的action后,映射转换为应用自有api
2.3 意图执行部分
各应用自有api调用系统api,执行系统接口实现用户意图